
Beyond CrowdStrike: Proactive Measures You Need to Take to Mitigate Your Cyber Risk
By Jacqueline Lebo, Resha Chheda & Vinayak Wadhwa
In the world of cybersecurity, the CrowdStrike outage last week serves as a stark reminder of the vulnerabilities that even the most robust systems can have. Cyber risk professionals must take proactive steps to ensure that such disruptions do not impact their organizations. This blog post aims to provide insights into the incident, discuss the importance of risk-based third-party assessments, and offer practical strategies for mitigating similar risks.
The CrowdStrike Outage: What Happened and Why
Understanding the Incident
CrowdStrike, a leader in endpoint security, experienced a significant outage that left many clients scrambling to maintain their cybersecurity defenses. The outage disrupted services, causing delays in threat detection and response times. This incident highlighted the potential weaknesses that even top-tier cybersecurity solutions can have.
Root Causes of the Outage
The primary cause of the CrowdStrike outage was a critical failure in their cloud infrastructure, a buggy code update in CrowdStrike’s Falcon monitoring product. This antivirus platform, which operates with deep system access on devices like laptops, servers, and routers, is designed to detect malware and suspicious activity. Falcon requires frequent updates to defend against new threats but this time, the update intended to bolster security and stability did the opposite.
FAIR-MAM Analysis: CrowdStrike Outage Costs Likely Manageable: Our risk quantification model shows some good news (but not for Delta Air Lines). Learn more.
The Impact on Businesses
For businesses relying on CrowdStrike for their endpoint security, the outage translated to increased vulnerability to cyberattacks. Teams faced delays in receiving threat alerts, leaving systems exposed to potential breaches. Furthermore, the incident underscored the importance of having contingency plans and backup solutions in place to maintain security during such outages.
Mitigate the Impact of a ‘CrowdStrike-like’ Incident on Your Organization
1. Implement a Risk-Based Approach to Third-Party Risk Management
Importance of Assessing Third-Party Risks
Third-party vendors play a crucial role in modern business operations, but they also introduce additional risks. A risk-based approach to evaluating these vendors ensures that organizations prioritize resources effectively and focus on the most significant threats.
Identifying High-Risk Vendors
Cyber risk professionals can identify which third-party relationships pose the greatest risk by categorizing vendors based on the criticality of the services they provide. For instance, vendors with access to sensitive data or those providing essential security services should be subject to more rigorous assessments.
Implementing Continuous Monitoring
Continuous monitoring of third-party vendors is essential to ensure ongoing compliance and risk mitigation. Automated tools can help track changes in vendor risk profiles, enabling organizations to respond quickly to emerging threats.
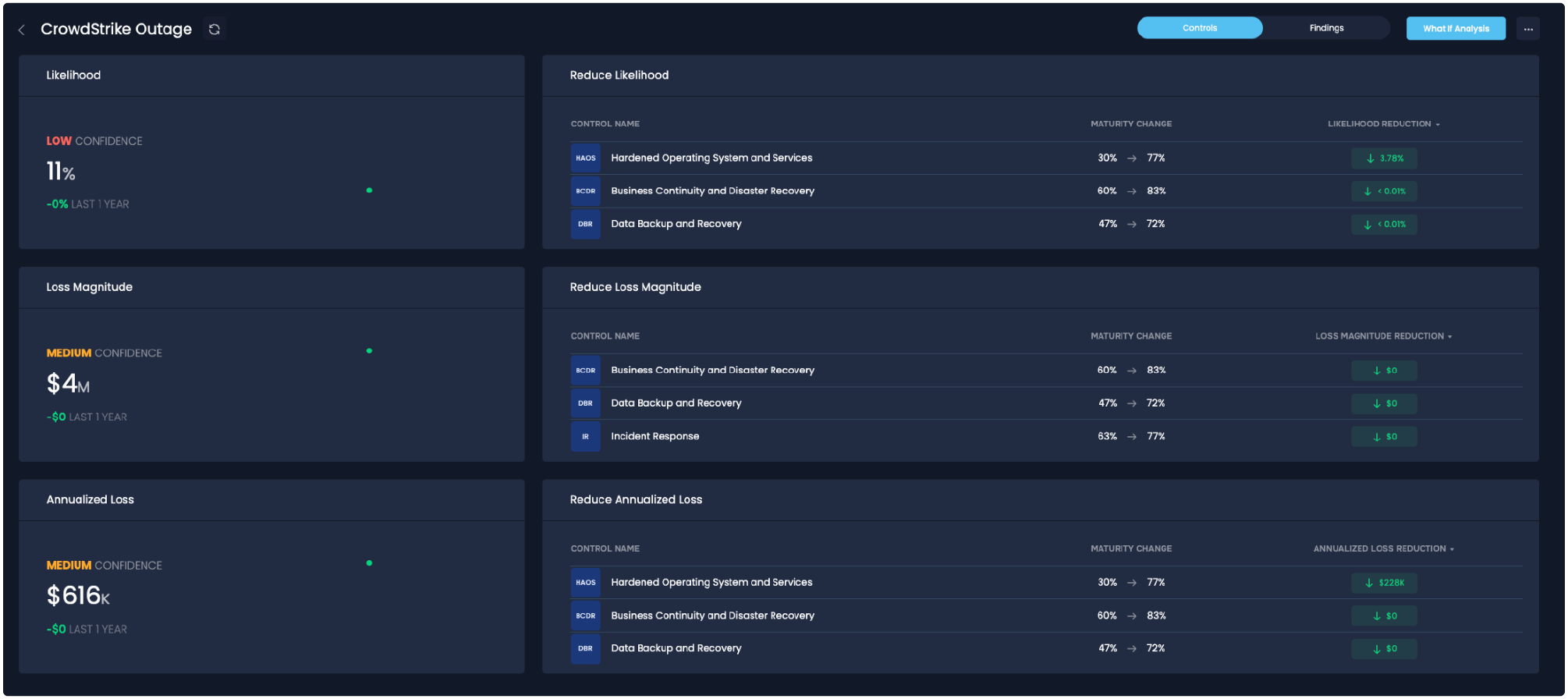
2. High-Risk Asset Grouping and Tagging for Risk Quantification
Defining High-Risk Assets
High-risk assets are those that, if compromised, could have a significant impact on an organization’s operations, reputation, or financial stability. These assets often include sensitive data, critical infrastructure, and key business applications. It is important to note that critical assets go beyond just the applications; as we saw with CrowdStrike, this includes the servers and endpoints needed to run them.
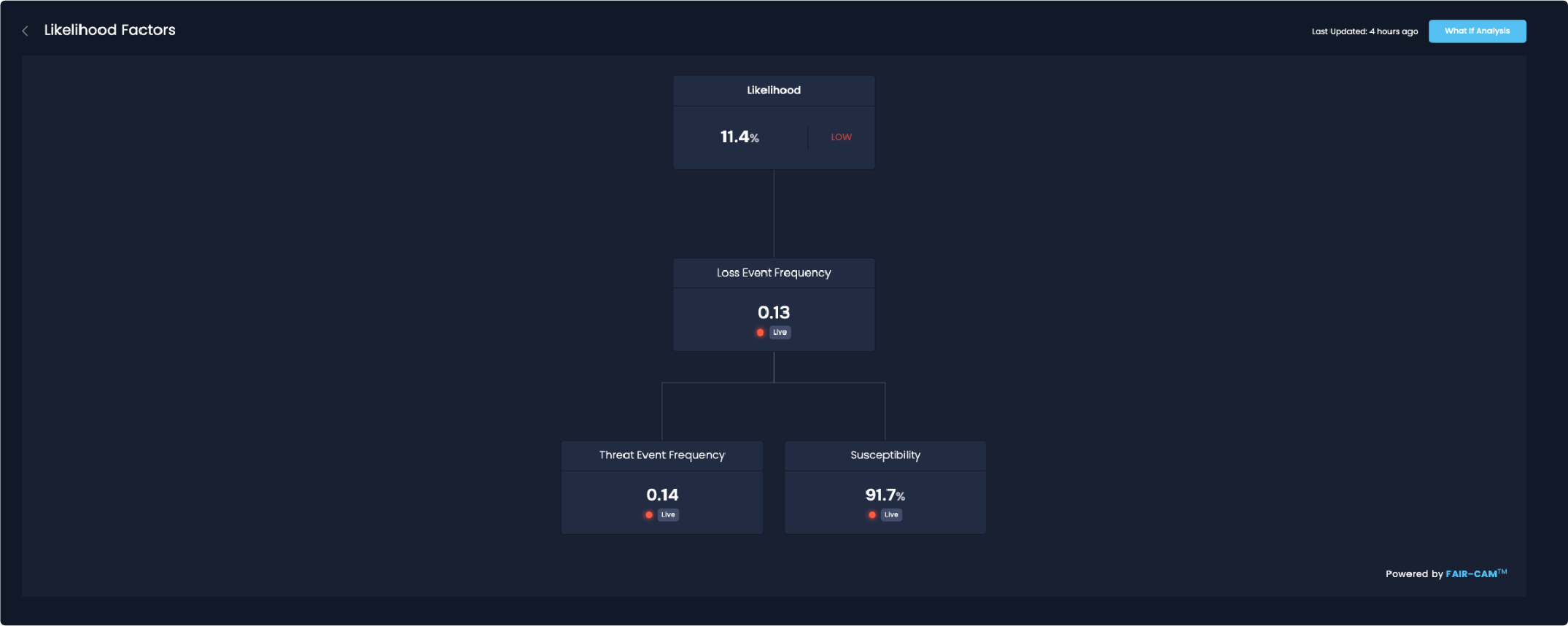
Quantifying the Risk
Quantifying the risk associated with high-risk assets involves evaluating the probable impact of a security incident, such as outages and breaches, and the likelihood of such an event occurring.
Tagging and Prioritizing High-Risk Assets
Using tagging systems to group and prioritize assets helps ensure that security efforts are focused where they are needed most. Tags can denote the asset’s sensitivity, criticality, and level of exposure, aiding in the development of targeted security strategies. For instance, if you have a group of servers that all support a large application with endpoints. You can group these together to ensure your controls are functioning effectively across all layers of technology.
A Real-Life Example: A large healthcare technology organization we work with has been using the SAFE One platform to tag assets that are a critical and high priority in order to understand what controls can drive down their risk of things such as business interruption (like the CrowdStrike incident) and ransomware. This is important to their business because they have limited resources and need to ensure their roadmap aligns with where the most risk is.
3. Controls Reliability Deviation: Understanding the Impact of Individual Controls
The Importance of Control Reliability
Security controls are measures put in place to protect an organization’s assets from threats. The reliability of these controls is crucial, as even a single failure can lead to significant risk exposure. Multiple control failures across layers of security can lead to events such as the CrowdStrike outage, which can have a large impact over days.
Assessing Control Reliability
Regularly assessing the effectiveness of security controls helps identify weaknesses and areas for improvement. This can involve automated testing, manual audits, and performance monitoring to ensure controls function as intended.
The Ripple Effect of Control Failures
A failure in a single security control can have a cascading effect, leading to increased vulnerability and risk. For example, if an antivirus solution fails to update correctly, it may expose systems to new threats, potentially resulting in a widespread breach. Following the CrowdStrike outage on Friday, we witnessed the failure of disaster recovery controls across several businesses and service lines. In moving into a remote environment most businesses did not account for the fact that IT staff would not be readily available everywhere to reset devices if required manually.
A Real Life Example: A large hospital system recently used the platform in order to justify the spend to enhance their Business continuity and disaster recovery (BCDR) program (after the CrowdStrike incident) and to understand how removing CrowdStrike from their environment would increase risk across their attack surface.
SAFE One Use Case with Outage Risk Scenario
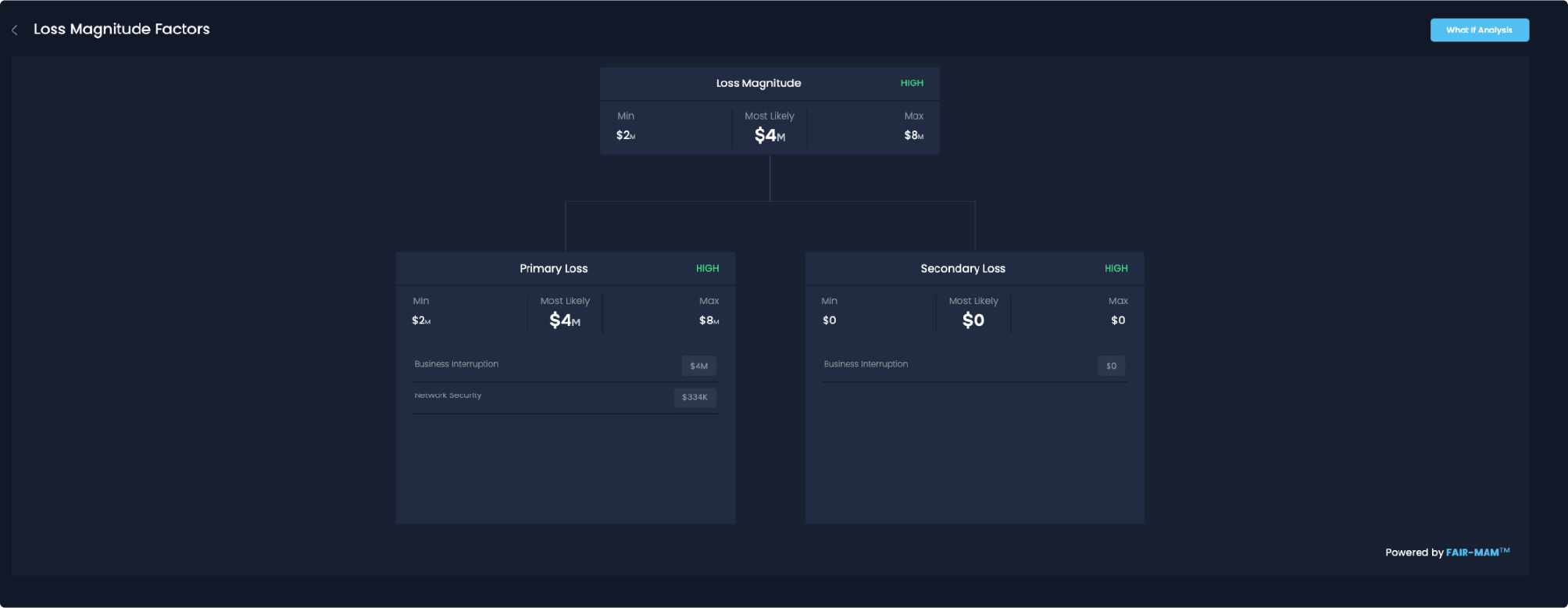
Using the SAFE One platform incorporating the FAIR-MAM loss model, a large retail organization was able to model out the scenario concentrating on losses resulting from the business interruption and the response required. FAIR-MAM showed that their business had probable losses focused in the categories of business interruption and network security (response). The total projected losses were around half a million dollars. They were then able to use this information in order to understand which controls would drive this risk down in the future because, unfortunately, in a world where we are reliant on third parties, this won’t be the last time.
Staying Ahead with a Risk-Based Approach
The CrowdStrike outage serves as a powerful reminder of the importance of robust cybersecurity measures and proactive risk management. By adopting a risk-based approach to third-party assessments, prioritizing high-risk assets, ensuring control reliability, and utilizing frameworks through SAFE One, cyber risk professionals can better safeguard their organizations against future incidents. Stay proactive, stay prepared, and keep your cyber defenses strong. For further insights and expert guidance, consider reaching out to our team of cybersecurity professionals who can help you develop and implement effective risk management strategies tailored to your organization’s unique needs. Contact us for a demo!


